Comparison Redux vs IPAdapter.
24 Noviembre 2024 at 11:28
| | submitted by /u/Total-Resort-3120 [link] [comments] |
| | What is Redux: https://www.youtube.com/watch?v=YSJsejH5Viw Illustration of Redux as a style transfer tool. Basically, it is possible to change the strength of the style transfer effect to get an image that actually follows the prompt. The issue is that going for a constant strength doesn't work that well. This is why I made a node that increase the strength linearly through the steps so that the style transfer gets smoother. For example here I decided to start the generation at strength 0 (no style transfer), and then that strength value grows linearly from 0 to 1 for the first 9 steps, this is the setting that was used for the Picasso style transfer above. You can download the node here: https://files.catbox.moe/rndi8m.rar You extract the "ComfyUI-FloatRamp" folder and put it on "ComfyUI\custom_nodes" You can also use this workflow and try it out with this image reference. That workflow also needs some other custom nodes to work proprely: https://github.com/cubiq/ComfyUI_essentials https://github.com/kijai/ComfyUI-KJNodes https://reddit.com/r/StableDiffusion/comments/1el79h3/flux_can_be_run_on_a_multigpu_configuration/ [link] [comments] |
| | Intro: If you haven't seen it yet, there's a new model called Mochi 1 that displays incredible video capabilities, and the good news for us is that it's local and has an Apache 2.0 licence: https://x.com/genmoai/status/1848762405779574990 Our overloard kijai made a ComfyUi node that makes this feat possible in the first place, here's how it works:
How to install: 1) Go to the ComfyUI_windows_portable\ComfyUI\custom_nodes folder, open cmd and type this command:
2) Go to the ComfyUI_windows_portable\update folder, open cmd and type those 2 commands:
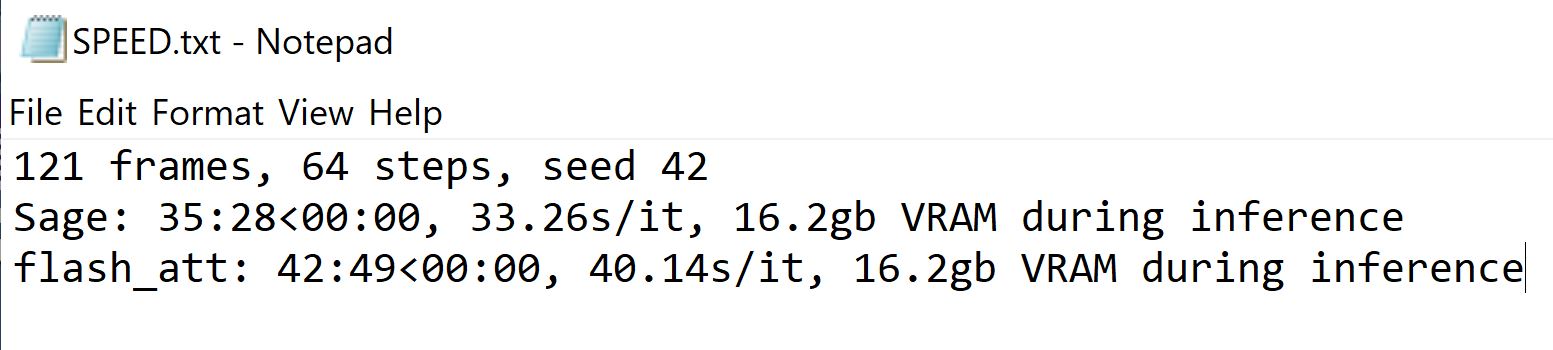
3) You have 3 optimization choices when running this model, sdpa, flash_attn and sage_attn sage_attn is the fastest of the 3, so only this one will matter there. Go to the ComfyUI_windows_portable\update folder, open cmd and type this command:
4) To use sage_attn you need triton, for windows it's quite tricky to install but it's definitely possible: - I highly suggest you to have torch 2.5.0 + cuda 12.4 to keep things running smoothly, if you're not sure you have it, go to the ComfyUI_windows_portable\update folder, open cmd and type this command:
- Once you've done that, go to this link: https://github.com/woct0rdho/triton-windows/releases/tag/v3.1.0-windows.post5, download the triton-3.1.0-cp311-cp311-win_amd64.whl binary and put it on the ComfyUI_windows_portable\update folder - Go to the ComfyUI_windows_portable\update folder, open cmd and type this command:
5) Triton still won't work if we don't do this: - Install python 3.11.9 on your computer - Go to C:\Users\Home\AppData\Local\Programs\Python\Python311 and copy the libs and include folders - Paste those folders onto ComfyUI_windows_portable\python_embeded Triton and sage attention should be working now. 6) Download the fp8 or the bf16 model - Go to ComfyUI_windows_portable\ComfyUI\models and create a folder named "diffusion_models" - Go to ComfyUI_windows_portable\ComfyUI\models\diffusion_models, create a folder named "mochi" and put your model in there. 7) Download the VAE - Go to ComfyUI_windows_portable\ComfyUI\models\vae, create a folder named "mochi" and put your VAE in there 8) Download the text encoder - Go to ComfyUI_windows_portable\ComfyUI\models\clip, and put your text encoder in there. And there you have it, now that everything is settled in, load this workflow on ComfyUi and you can make your own AI videos, have fun! A 22 years old woman dancing in a Hotel Room, she is holding a Pikachu plush [link] [comments] |
![[link]](https://i.redd.it/auhdqne94u2e1.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[link]](https://i.redd.it/1xnkv43srhud1.png){kind=link}
![[link]](https://i.redd.it/3ehphbe566ud1.png){kind=link}
![[link]](https://i.redd.it/o1trjal2gntd1.jpeg){kind=link}