Faster Integer Division with Floating Point
Multiplication on a common microcontroller is easy. But division is much more difficult. Even with hardware assistance, a 32-bit division on a modern 64-bit x86 CPU can run between 9 and 15 cycles. Doing array processing with SIMD (single instruction multiple data) instructions like AVX or NEON often don’t offer division at all (although the RISC-V vector extensions do). However, many processors support floating point division. Does it make sense to use floating point division to replace simpler division? According to [Wojciech Mula] in a recent post, the answer is yes.
The plan is simple: cast the 8-bit numbers into 32-bit integers and then to floating point numbers. These can be divided in bulk via the SIMD instructions and then converted in reverse to the 8-bit result. You can find several code examples on GitHub.
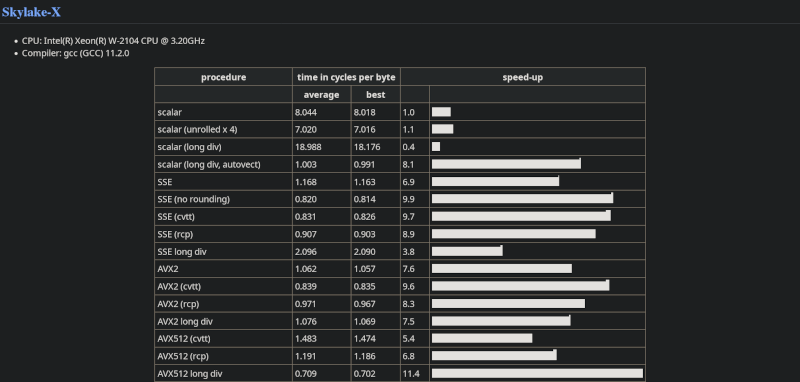
Since modern processors have several SIMD instructions, the post takes the time to benchmark many different variations of a program dividing in a loop. The basic program is the reference and, thus, has a “speed factor” of 1. Unrolling the loop, a common loop optimization technique, doesn’t help much and, on some CPUs, can make the loop slower.
Converting to floating point and using AVX2 sped the program up by a factor of 8X to 11X, depending on the CPU. Some of the processors supported AVX512, which also offered considerable speed-ups.
This is one of those examples of why profiling is so important. If you’d had asked us if converting integer division to floating point might make a program run faster, we’d have bet the answer was no, but we’d have been wrong.
As CPUs get more complex, optimizing gets a lot less intuitive. If you are interested in things like AVX-512, we’ve got you covered.