By default, bash is the most popular command language simply because it’s included in most *nix operating systems. Additionally, people don’t tend to spend a lot of time thinking about whatever their computer uses for scripting as they might for other pieces of software like a word processor or browser. If you are so inclined to take a closer look at this tool that’s often taken for granted, there are a number of alternatives to bash and [monzool] wanted to investigate them closely.
Unlike other similar documentation that [monzool] has come across where the writers didn’t actually use the scripting languages being investigated, [monzool] is planning to use each of these and accomplish specific objectives. This will allow them to get a feel for the languages and whether or not they are acceptable alternatives for bash. Moving through directories, passing commands back and forth, manipulating strings, searching for files, and manipulating the terminal display settings are all included in this task list. A few languages are tossed out before initial testing even begins for not meeting certain specific requirements. One example is not being particularly useful in [monzool]’s preferred embedded environments, but even so there are enough bash alternatives to test out ten separate languages.
Unfortunately, at the end of the day none of the ten selected would make a true replacement for bash, at least for [monzool]’s use case, but there were a few standouts nonetheless. Nutshell was interesting for being a more modern, advanced system and [monzool] found Janet to be a fun and interesting project but had limitations with cross-compiling. All in all though this seemed to be an enjoyable experience that we’d recommend if you actually want to get into the weeds on what scripting languages are actually capable of. Another interesting one we featured a while back attempts to perform as a shell and a programming language simultaneously.
Life was simpler when everything your computer did was text-based. It is easy enough to shove data into one end of a pipe and take it out of the other. Sure, if the pipe extends across the network, you might have to call it a socket and take some special care. But how do you pipe all the data we care about these days? In particular, I found I wanted to transport audio from the output of one program to the input of another. Like most things in Linux, there are many ways you can get this done and — like most things in Linux — only some of those ways will work depending on your setup.
Why?
There are many reasons you might want to take an audio output and process it through a program that expects audio input. In my case, it was ham radio software. I’ve been working on making it possible to operate my station remotely. If all you want to do is talk, it is easy to find software that will connect you over the network.
However, if you want to do digital modes like PSK31, RTTY, or FT8, you may have a problem. The software to handle those modes all expect audio from a soundcard. They also want to send audio to a soundcard. But, in this case, the data is coming from a program.
Of course, one answer is to remote desktop into the computer directly connected to the radio. However, most remote desktop solutions aren’t made for high-fidelity and low-latency audio. Plus, it is nice to have apps running directly on your computer.
I’ll talk about how I’ve remoted my station in a future post, but for right now, just assume we want to get a program’s audio output into another program’s audio input.
Sound System Overview
Someone once said, “The nice thing about standards is there are so many of them.” This is true for Linux sound, too. The most common way to access a soundcard is via ALSA, also known as Advanced Linux Sound Architecture. There are other methods, but this is somewhat the lowest common denominator on most modern systems.
However, most modern systems add one or more layers so you can do things like easily redirect sound from a speaker to a headphone, for example. Or ship audio over the network.
The most common layer over ALSA is PulseAudio, and for many years, it was the most common standard. These days, you see many distros moving to PipeWire.
PipeWire is newer and has a lot of features but perhaps the best one is that it is easy to set it up to look like PulseAudio. So software that understands PipeWire can use it. Programs that don’t understand it can pretend it is PulseAudio.
There are other systems, too, and they all interoperate in some way. While OSS is not as common as it once was, JACK is still found in certain applications. Many choices!
One Way
There are many ways you can accomplish what I was after. Since I am running PipeWire, I elected to use qpwgraph, which is a GUI that shows you all the sound devices on the system and lets you drag lines between them.
It is super powerful but also super cranky. As things change, it tends to want to redraw the “graph,” and it often does it in a strange and ugly way. If you name a block to help you remember what it is and then disconnect it, the name usually goes back to the default. But these are small problems, and you can work around them.
In theory, you should be able to just grab the output and “wire” it to the other program’s input. In fact, that works, but there is one small problem. Both PipeWire and PulseAudio will show when a program is making sound, and then, when it stops, the source vanishes.
This makes it very hard to set up what I wanted. I wound up using a loopback device so there was something for the receiver to connect to and the transient sending device.
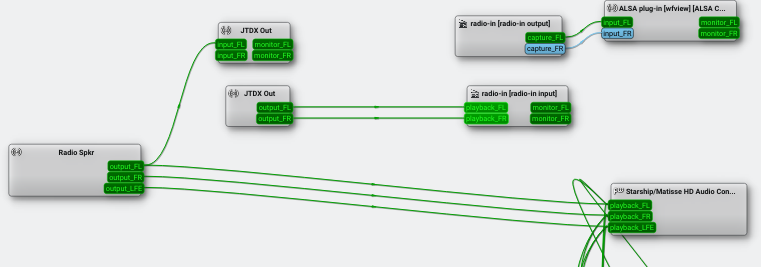
Here’s the graph I wound up with:
A partial display of the PipeWire configuration
I omitted some of the devices and streams that didn’t matter, so it looks pretty simple. The box near the bottom right represents my main speakers. Note that the radio speaker device (far left) has outputs to the speaker and to the JTDX in box.
This lets me hear the audio from the radio and allows JTDX to decode the FT8 traffic. Sending is a little more complicated.
The radio-in boxes are the loopback device. You can see it hooked to the JTDX out box because when I took the screenshot, I was transmitting. If I were not transmitting, the out box would vanish, and only the pipe would be there.
Everything that goes to the pipe’s input also shows up as the pipe’s output and that’s connected directly to the radio input. I left that box marked with the default name instead of renaming it so you can see why it is worth renaming these boxes! If you hover over the box, you’ll see the full name which does have the application name in it.
That means JTDX has to be set to listen and send to the streams in question. The radio also has to be set to the correct input and output. Usually, setting them to Pulse will work, although you might have better luck with the actual pipe or sink/source name.
In order to make this work, though, I had to create the loopback device:
This creates the device as a sink with stereo channels that connect to nothing by default. Sometimes, I only connect the left channels since that’s all I need, but you may need something different.
Other Ways
There are many ways to accomplish this, including using the pw-link utility or setting up special configurations. The PipeWire documentation has a page that covers at least most of the scenarios.
You can also create this kind of virtual device and wiring with PulseAudio. If you need to do that, investigate the pactl command and use it to load the module-loopback module.
It is even possible to use the snd-aloop module to create loopback devices. However, PipeWire seems to be the future, so unless you are on an older system, it is probably better to stick to that method.
Sound Off!
What’s your favorite way to route audio? Why do you do it? What will you do with it? I’ll have a post detailing how this works to allow remote access to a ham transceiver, although this is just a part of the equation. It would be easy enough to use something like this and socat to stream audio around the network in fun ways.
We’ve talked about PipeWire for audio and video before. Of course, connecting blocks for audio processing makes us want to do more GNU Radio.
Imagine you own a weather station. Then imagine that after some years have passed, you’ve had to replace one of the sensors multiple times. Your new problem is that the sensor is no longer available. What does a hacker like [Luca] do? Build a custom solution, of course!
[Luca]’s work concerns the La Crosse WS-9257F-IT weather station, and the repeat failures of the TX44DTH-IT external sensor. Thankfully, [Luca] found that the weather station’s communication protocol had been thoroughly reverse-engineered by [Fred], among others. He then set about creating a bridge to take humidity and temperature data from Zigbee sensors hooked up to his Home Assistant hub, and send it to the La Crosse weather station. This was achieved with the aid of a SX1276 LoRa module on a TTGO LoRa board. Details are on GitHub for the curious.
Luca didn’t just work on the Home Assistant integration, though. A standalone sensor was also developed, based on the Xiao SAMD21 microcontroller board and a BME280 temperature, pressure, and humidity sensor. It too can integrate with the Lacrosse weather station, and proved useful for one of [Luca’s] friends who was in the same boat.
Ultimately, it sucks when a manufacturer no longer supports hardware that you love and use every day. However, the hacking community has a way of working around such trifling limitations. It’s something to be proud of—as the corporate world leaves hardware behind, the hackers pick up the slack!
Most of us associate echolocation with bats. These amazing creatures are able to chirp at frequencies beyond the limit of our hearing, and they use the reflected sound to map the world around them. It’s the perfect technology for navigating pitch-dark cave systems, so it’s understandable why evolution drove down this innovative path.
Humans, on the other hand, have far more limited hearing, and we’re not great chirpers, either. And yet, it turns out we can learn this remarkable skill, too. In fact, research suggests it’s far more achievable than you might think—for the sighted and vision impaired alike!
Bounce That Sound
Bats are the most famous biologcal users of echolocation. Credit: Petteri Aimonen
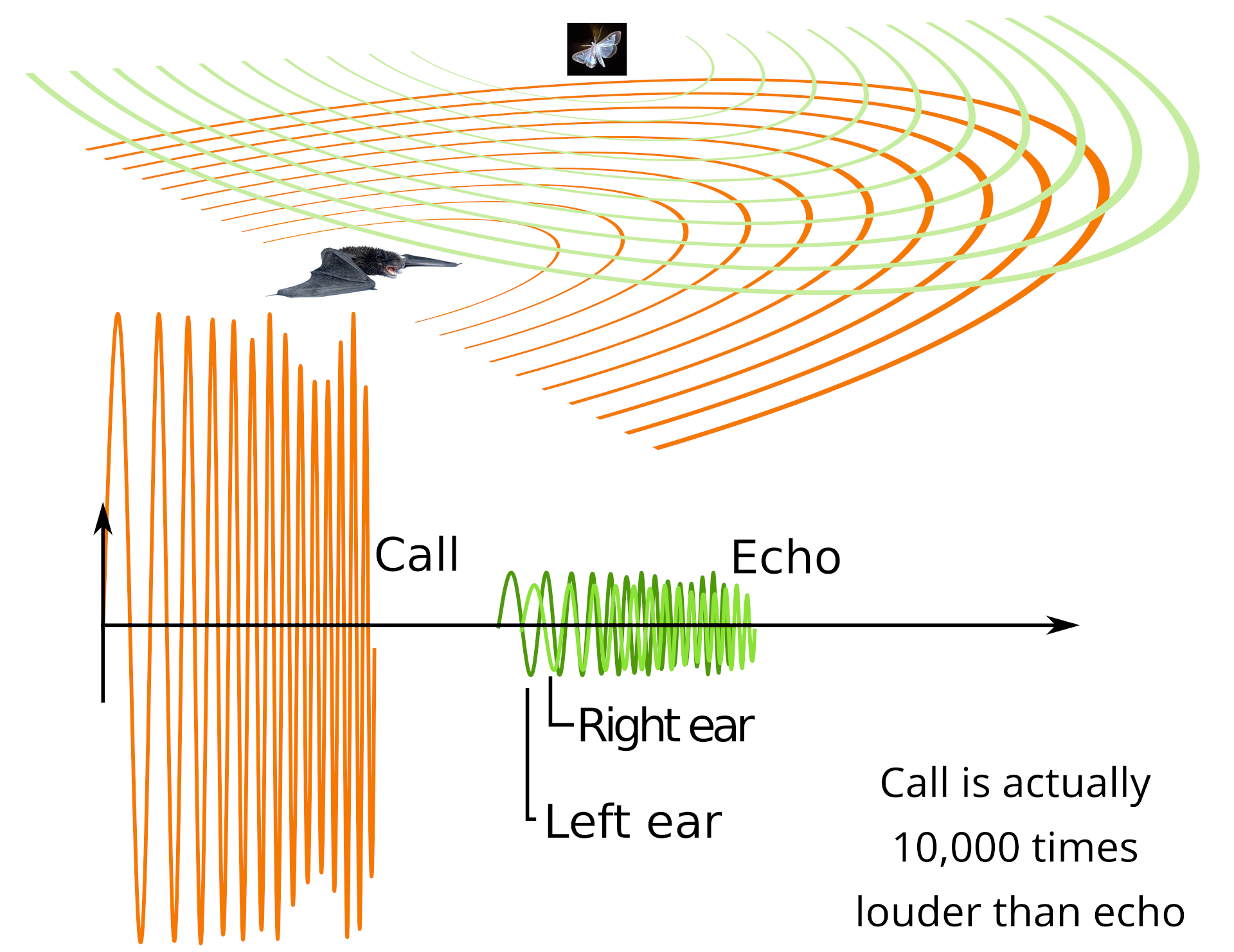
Before we talk about humans using echolocation, let’s examine how the pros do it. Bats are nature’s acoustic engineers, emitting rapid-fire ultrasonic pulses from their larynx that can range from 11 kHz to over 200 kHz. Much of that range is far beyond human hearing, which tops out at under 20 kHz. As these sound waves bounce off objects in their environment, the bat’s specialized ultrasonic-capable ears capture the returning echoes. Their brain then processes these echoes in real-time, comparing the outgoing and incoming signals to construct a detailed 3D map of their surroundings. The differences in echo timing tell them how far away objects are, while variations in frequency and amplitude reveal information about size, texture, and even movement. Bats will vary between constant-frequency chirps and frequency-modulated tones depending on where they’re flying and what they’re trying to achieve, such as navigating a dark cavern or chasing prey. This biological sonar is so precise that bats can use it to track tiny insects while flying at speed.
Humans can’t naturally produce sounds in the ultrasonic frequency range. Nor could we hear them if we did. That doesn’t mean we can’t echolocate, though—it just means we don’t have quite the same level of equipment as the average bat. Instead, humans can achieve relatively basic echolocation using simple tongue clicks. In fact, a research paper from 2021 outlined that skills in this area can be developed with as little as a 10-week training program. Over this period, researchers successfully taught echolocation to both sighted and blind participants using a combination of practical exercises and virtual training. A group of 14 sighted and 12 blind participants took part, with the former using blindfolds to negate their vision.
The aim of the research was to investigate click-based echolocation in humans. When a person makes a sharp click with their tongue, they’re essentially launching a sonic probe into their environment. As these sound waves radiate outward, they reflect off surfaces and return to the ears with subtle changes. A flat wall creates a different echo signature than a rounded pole, while soft materials absorb more sound than hard surfaces. The timing between click and echo precisely encodes distance, while differences between the echoes reaching each ear allows for direction finding.
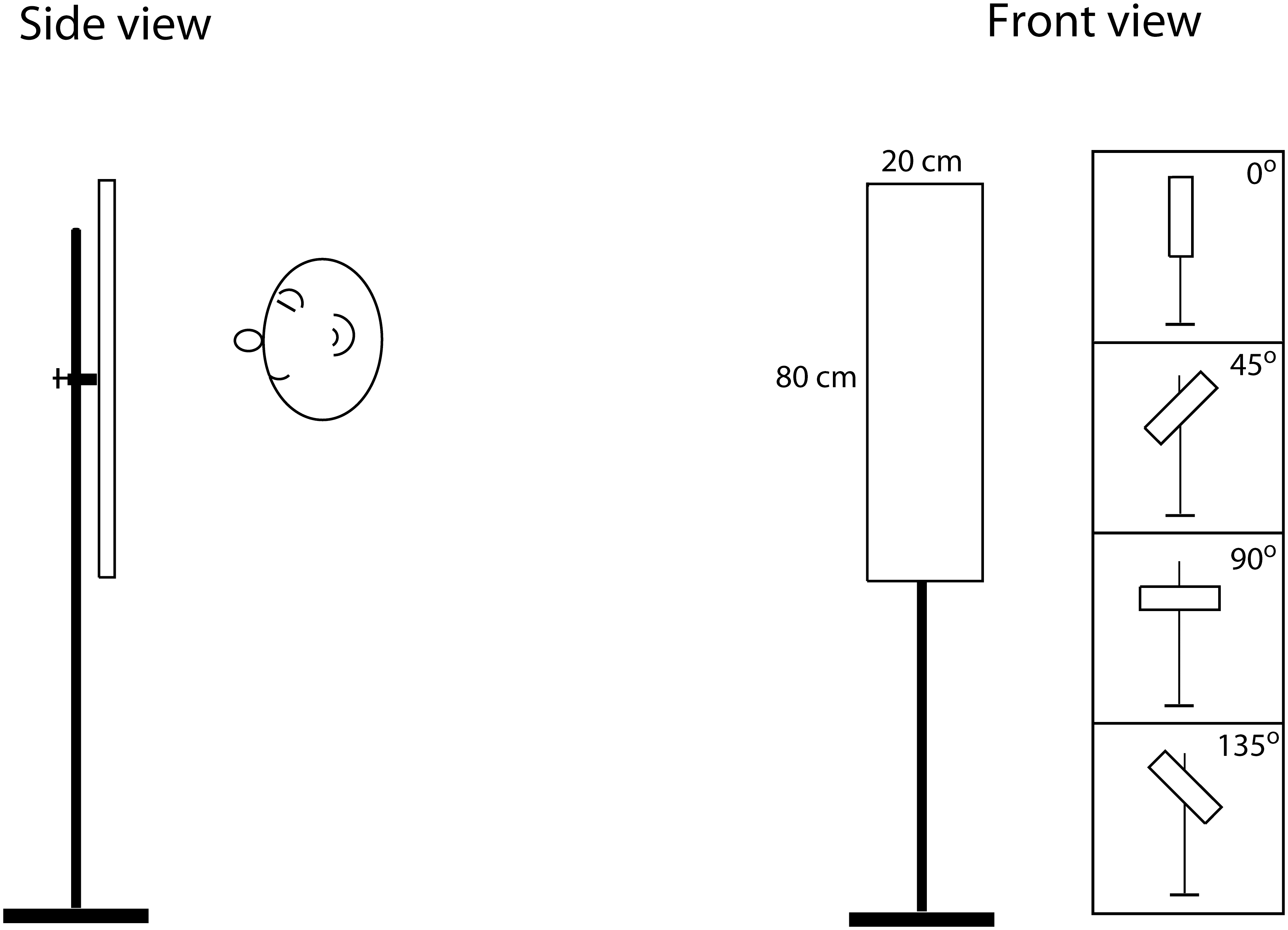
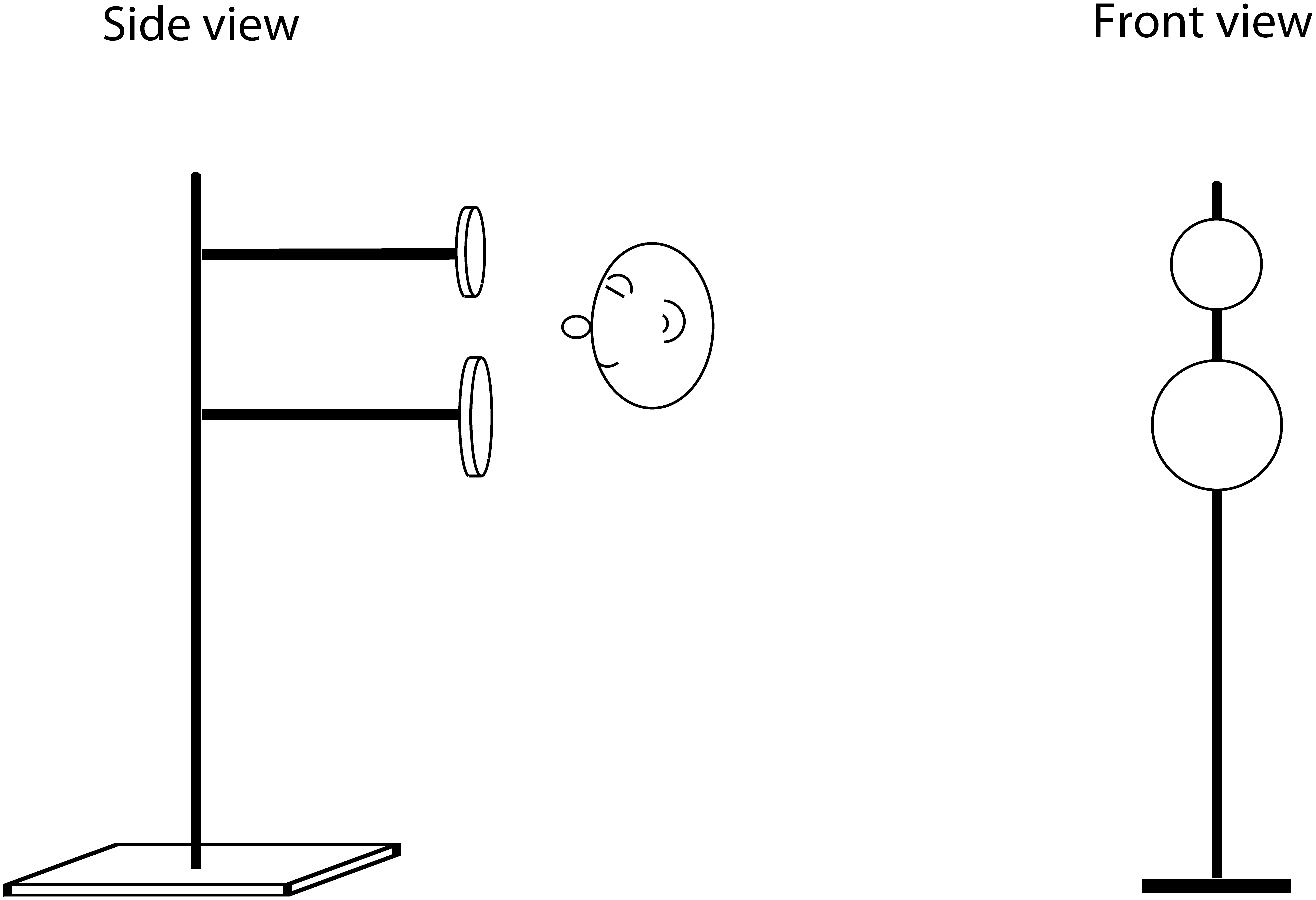
The orientation task involved asking participants to use mouth clicks to determine the way a rectangular object was oriented in front of them. Credit: research paperThe size discrimination task asked participants to determine which disc was bigger solely using echolocation. Credit: research paper
The training regime consisted of a variety of simple tasks. The researchers aimed to train participants on size discrimination, with participants facing two foam board disks mounted on metal poles. They had to effectively determine which foam disc was larger using only their mouth clicks and their hearing. The program also included an orientation challenge, which used a single rectangular board that could be rotated to different angles. The participants had to again use clicks and their hearing to determine the orientation of the board. These basic tools allowed participants to develop increasingly refined echo-sensing abilities in a controlled environment.
Perhaps the most intriguing part of the training involved a navigation task in a virtually simulated maze. Researchers first created special binaural recordings of a mannikin moving through a real-world maze, making clicks as it went. They then created virtual mazes that participants could navigate using keyboard controls. As they navigated through the virtual maze, without vision, the participants would hear the relevant echo signature recorded in the real maze. The idea was to allow participants to build mental maps of virtual spaces using only acoustic information. This provided a safe, controlled environment for developing advanced navigation skills before applying them in the real world. Participants also attempted using echolocation to navigate in the real world, navigating freely with experimenters on hand to guide them if needed.
Participants were trained to navigate a virtual maze using audio cues only. Credit: research paper
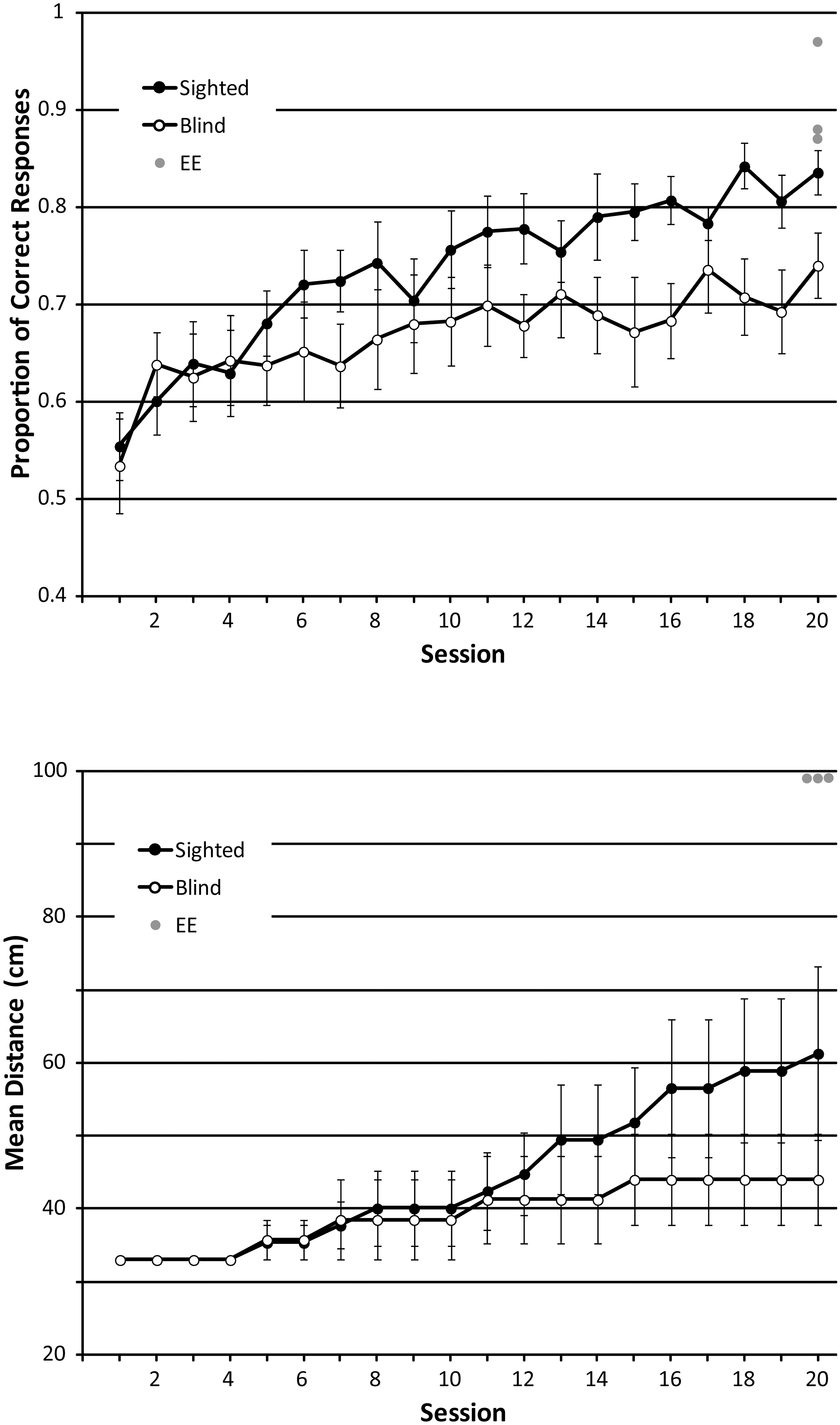
The most surprising finding wasn’t that people could learn echolocation – it was how accessible the skill proved to be. Previous assumptions about age and visual status being major factors in learning echolocation turned out to be largely unfounded. While younger participants showed some advantages in the computer-based exercises, the core skill of practical echolocation was accessible to all participants. After 10 weeks of training, participants were able to correctly answer the size discrimination task over 75% of the time, and at increased range compared to when they began. Orientation discrimination also improved greatly over the test period to a success rate over 60% for the cohort. Virtual maze completion times also dropped by over 50%.
Over time, participants improved in all tasks—particularly the size discrimination task, as seen in the results on this graph. The difficulty level of tasks were also scaled over time, presenting greater challenge as participants improved their echolocation skills. Credit: research paper
The study also involved a follow-up three months later with the blind members of the cohort. Participants credited the training with improving their spatial awareness, and some noted they had begun to use the technique to find doors or exits, or to make their way through strange places.
What’s particularly fascinating is how this challenges our understanding of basic human sensory capabilities. Echolocation doesn’t involve adding new sensors or augmenting existing ones—it’s just about training the brain to extract more information from signals it already receives. It’s a reminder that human perception is far more plastic than we often assume.
The researchers suggest that echolocation training should be integrated into standard mobility training for visually impaired individuals. Given the relatively short training period needed to develop functional echo-sensing abilities, it’s hard to argue against its inclusion. We might be standing at the threshold of a broader acceptance of human echolocation, not as an exotic capability, but as a practical skill that anyone can learn.
I recently spent an unreasonable amount of time looking into some of the self-hosted analytics tools that I've seen mentioned here. I wrote up the results of my research into self-hosted analytics tools in a blog post that I wanted to share here because there seem to be few if any resources out there that directly compare my two top contenders, Umami and Plausible.
All of the platforms I looked at offer privacy-compliant, cookie-free, client-side analytics. My focus was mainly on how easy or difficult it is to set up and administer each platform using docker compose. Apologies to any serious Matomo fans out there; I don't use PHP, which makes Matomo seem a lot more complicated to me. I do have a section that briefly mentions other tools at the end, but I couldn't look into everything.
A lot is made of the fact that Plausible uses ClickHouse while Umami uses PostgreSQL for data storage, but the difference hasn't been noticeable on my (probably over-specced) dedicated server. YMMV.
Having used both Umami and Plausible now, I can sum it all up like this: Umami is easier to set up and collects more complete data, while Plausible has a slicker but more branded user interface.
I am currenty planning the hardware for my first server build that's more than an old Celeron Thin Client. I want it to run a full *arr-Stack, Jellyfin, NAS/Cloud, Immich, Game Servers and various other small services like Lube Logger etc.
For the CPU i would like to go with something like an i3-14100 or a Ryzen 5 5500GT and no external GPU. Also the Ryzen 5 Pro 4650G & 5650G look pretty interresting because they support ECC. No comparable Intel CPU does that. The AMD APUs are faster in the common benchmarks and overall I prefer AMD over Intel. Also they are a bit cheaper, especially when finding a good deal on a used Ryzen 5 Pro. On the other hand I heard that only Intels QSV hardware transcoding is the real deal when it comes to stuff like Plex/Jellyfin. I can't imagine that the AMD integrated graphics wouldn't be able to handle this kind of work.
Can anyone who knows a bit more about the topic help me with the choice or point me to good sources? Is there anything else which I forgot to look at when comparing these CPUs? Power consumption should be more or less the same.
I've built my own computers for 20+ years now. But my knowledge ebs and flows depending on how often I need it. Home networking and servers are new to me. So please forgive my ignorance and lack of terminology or misuse of terminology.
I'm currently using a synology NAS for plex. Maxed out drive size, and the fourth bay is nonfunctional.
I would rather not spend $1k on a new 8 bay synology NAS, but instead spend $2k on building my own expandable NAS /s. 😅
My needs from this NAS is about 90% Plex, 5% Photo backup (RAW files), and 1% data backup.
I do not need transcoding as I stream plex at full quality through an Nvidia shield. If I understand correctly.
Would like to support 8+ HDDs as I like 4k remux videos.
Would like a 10GB sfp+ NIC. I have 10GB from my personal computer to the switch.
I'm leaning towards Unraid or Truenas. It seems that hardware RAID is no longer needed for a home server. Do either support the use of power top (or something similar) for checking C-states?
Any good recommendations on HBAs and NICs that support ASPM?
Should I be looking for ECC memory?
It would be most excellent if I can keep my power usage at or better than what synology provides. It would be nice to have idle with all drives spun down to be 20W or less.
Hi, I'm currently doing a self-hosting website project and I want to do sth similar to a streaming site where the index.html file is in C:/ Drive but the files are in the HDD drive (G:/). Moving it to C is not an option because there are a lot of files in G:/ and there's not enough space in C:/. I prefer not moving the entirety of apache from C to G so what are my options
I have a Dell R720/PDU Dual 1100w Power Supplies rack mounted that's basically all that I have running in my rack. I would like a UPS that can keep them up when the power flickers so I don't loose all of my lab config on things like windows boxes or other things that I cannot backup easily through Eve-NG. It would be nice to have an uptime of 30mins but anything over 2mins would be nice.
Hi, I recently got an R640 server, and I’ve already installed two 6254 processors. Now, I’m deciding on the memory configuration. I’ve found that if all 24 memory slots are filled with 2933 modules, they will run at 2666 speed. Can anyone confirm this? Is it true that the speed will be reduced when all 24 slots are populated?
When Readarr downloads books, it organizes as follows:
Author >> Book Name
CWA, as well as Calibre, has a slightly different format"
Author >> Book Name (id_number)
id_number is a basic interger that increments by one each time a book is imported/added. Without this id_number, CWA does not see that a book has been added to the library.
As such, is it possible to use Readarr and CWA together? Maybe u/WasIstHierLos_ has some ideas?
how convoluted would it be to setup a trio of vms to accomplish the following
vm1 - *sense - takes the inet from the host and handles the routing for the vlab
vm2 - *pihole or similar (i know vm1 could handle this but its a learning experience)
vm3 - Linux box to test the above (if my assumption is correct, i wouldn't be able to access this if vm1 was not functioning correctly, and I would have ads/intentionally blocked domains if vm2 was not functioning properly)
eventually ill move this all to real hardware but i want to work out some software knowledge before i take it live
![[link]](https://i.redd.it/acjcoqts3a3e1.jpeg){kind=link}
![[link]](https://i.redd.it/b7tbb8j4z93e1.jpeg){kind=link}
![[link]](https://i.redd.it/7qld6mejoa3e1.png){kind=link}