Screens of Death: From Diagnostic Aids to a Sad Emoji
There comes a moment in the life of any operating system when an unforeseen event will tragically cut its uptime short. Whether it’s a sloppily written driver, a bug in the handling of an edge case or just dumb luck, suddenly there is nothing more that the OS’ kernel can do to salvage the situation. With its last few cycles it can still gather some diagnostic information, attempt to write this to a log or memory dump and then output a supportive message to the screen to let the user know that the kernel really did try its best.
This on-screen message is called many things, from a kernel panic message on Linux to a Blue Screen of Death (BSOD) on Windows since Windows 95, to a more contemplative message on AmigaOS and BeOS/Haiku. Over the decades these Screens of Death (SoD) have changed considerably, from the highly informative screens of Windows NT to the simplified BSOD of Windows 8 onwards with its prominent sad emoji that has drawn a modicum of ridicule.
Now it seems that the Windows BSOD is about to change again, and may not even be blue any more. So what’s got a user to think about these changes? What were we ever supposed to get out of these special screens?
Meditating On A Fatal Error

More important than the color of a fatal system error screen is what information it displays. After all, this is the sole direct clue the dismayed user gets when things go south, before sighing and hitting the reset button, followed by staring forlorn at the boot screen. After making it back into the OS, one can dig through the system logs for hints, but some information will only end up on the screen, such as when there is a storage drive issue.
The exact format of the information on these SoDs changes per OS and over time, with AmigaOS’ Guru Meditation screen being rather well-known. Although the naming was the result of an inside joke related to how the developers dealt with frequent system crashes, it stuck around in the production releases.
Interestingly, both Windows 9x and ME as well as AmigaOS have fatal and non-fatal special screens. In the case of AmigaOS you got a similar screen to the Guru Meditation screen with its error code, except in green and the optimistic notion that it might be possible to continue running after confirming the message. For Windows 9x/ME users this might be a familiar notion as well :
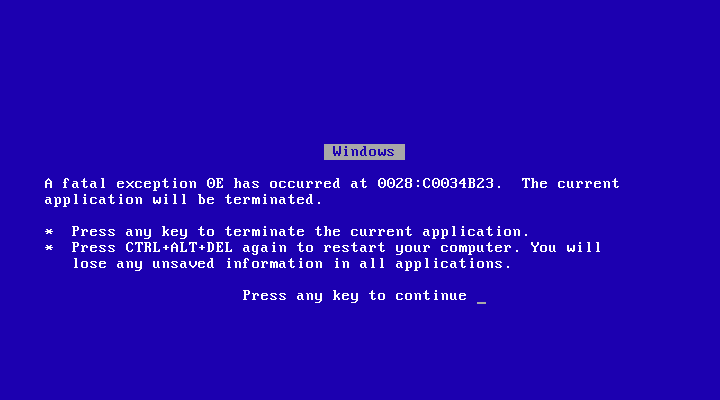
In this series of OSes you’d get these screens, with mashing a key usually returning you to a slightly miffed but generally still running OS minus the misbehaving application or driver. It could of course happen that you’d get stuck in an endless loop of these screens until you gave up and gave the three-finger salute to put Windows out of its misery. This was an interesting design choice, which Microsoft’s Raymond Chen readily admits to being somewhat quaint. What it did do was abandon the current event and return to the event dispatcher to give things another shot.

A characteristic of these BSODs in Windows 9x/ME was also that they didn’t give you a massive amount of information to work with regarding the reason for the rude interruption. Incidentally, over on the Apple side of the fence things were not much more elaborate in this regard, with OS X’s kernel panic message getting plastered over with a ‘Nothing to see here, please restart’ message. This has been quite a constant ever since the ‘Sad Mac’ days of Apple, with friendly messages rather than any ‘technobabble’.
This quite contrasts with the world of Windows NT, where even the already trimmed BSOD of Windows XP is roughly on the level of the business-focused Windows 2000 in terms of information. Of note is also that a BSOD on Windows NT-based OSes is a true ‘Screen of Death’, from which you absolutely are not returning.
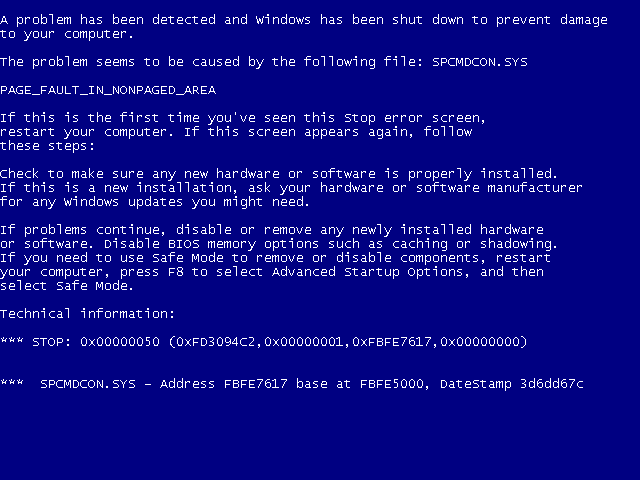
These BSODs provide a significant amount of information, including the faulting module, the fault type and some hexadecimal values that can conceivably help with narrowing down the fault. Compared to the absolute information overload in Windows NT 3.1 with a partial on-screen memory dump, the level of detail provided by Windows 2000 through Windows 7 is probably just enough for the average user to get started with.
It’s here interesting that more recent versions of Windows have opted to default to restarting automatically when a BSOD occurs, which renders what is displayed on them rather irrelevant. Maybe that’s why Windows 8 began to just omit that information and opted to instead show a generic ‘collecting information’ progress counter before restarting.
Times Are Changing

Although nobody was complaining about the style of BSODs in Windows 7, somehow Windows 8 ended up with the massive sad emoji plastered on the top half of the screen and no hexadecimal values, which would now hopefully be found in the system log. Windows 10 also added a big QR code that leads to some troubleshooting instructions. This overly friendly and non-technical BSOD mostly bemused and annoyed the tech community, which proceeded to brutally make fun of it.
In this context it’s interesting to see these latest BSOD screen mockups from Microsoft that will purportedly make their way to Windows 11 soon.
These new BSOD screens seem to have a black background (perhaps a ‘Black Screen of Death’?), omit the sad emoji and reduce the text to an absolute minimum:
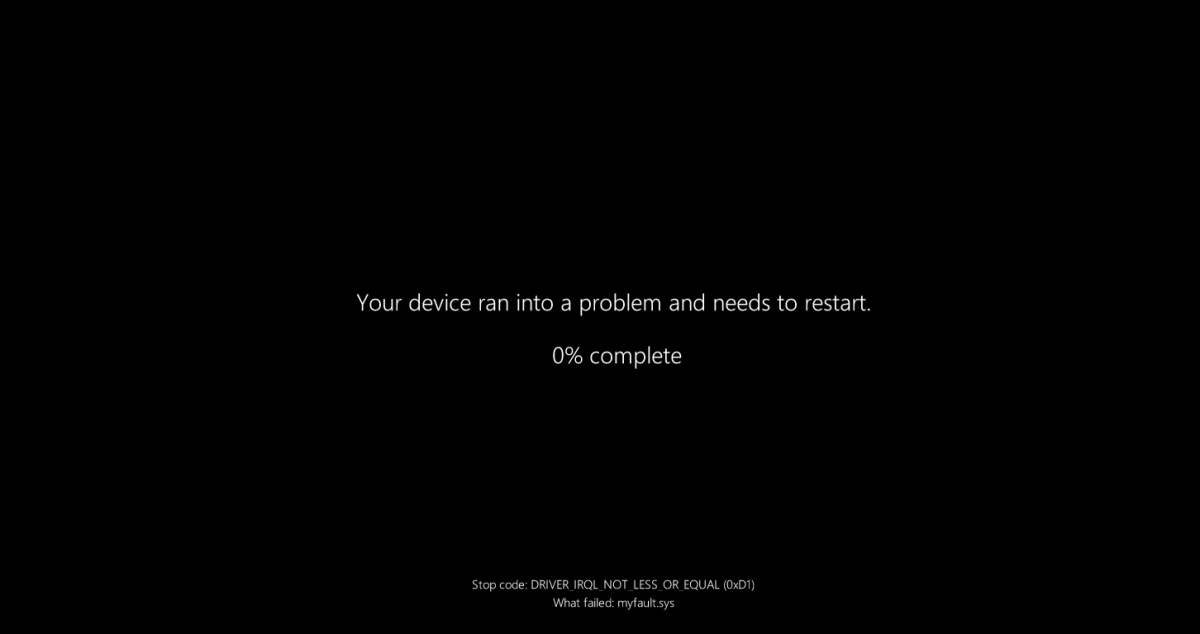
What’s noticeable here is how it makes the stop code very small on the bottom of the screen, with the faulting module below it in an even smaller font. This remains a big departure from the BSOD formats up till Windows 7 where such information was clearly printed on the screen, along with additional information that anyone could copy over to paper or snap a picture of for a quick diagnosis.
But Why
The crux here is whether Microsoft expects their users to use these SoDs for informative purposes, or whether they would rather that they get quickly forgotten about, as something shameful that users shouldn’t concern themselves with. It’s possible that they expect that the diagnostics get left to paid professionals, who would have to dig into the memory dumps, the system logs, and further information.
Whatever the case may be, it seems that the era of blue SoDs is well and truly over now in Windows. Gone too are any embellishments, general advice, and more in-depth debug information. This means that distinguishing the different causes behind a specific stop code, contained in the hexadecimal numbers, can only be teased out of the system log entry in Event Viewer, assuming it got in fact recorded and you’re not dealing with a boot partition or similar fundamental issue.
Although I’ll readily admit to not having seen many BSODs since probably Windows 2000 or XP — and those were on questionable hardware — the rarity of these events makes it in my view even more pertinent that these screens are as descriptive as possible, which is sadly not a feature that seems to be a priority for mainstream desktop OSes. Nor for niche OSes like Linux and BSD, tragically, where you have to know your way around the Systemd journalctl tool or equivalent to figure out where that kernel panic came from.
This is definitely a point where the SoD generated upon a fiery kernel explosion sets the tone for the user’s response.