Supersonic Flight May Finally Return to US Skies
After World War II, as early supersonic military aircraft were pushing the boundaries of flight, it seemed like a foregone conclusion that commercial aircraft would eventually fly faster than sound as the technology became better understood and more affordable. Indeed, by the 1960s the United States, Britain, France, and the Soviet Union all had plans to develop commercial transport aircraft capable flight beyond Mach 1 in various stages of development.

Yet today, the few examples of supersonic transport (SST) planes that actually ended up being built are in museums, and flight above Mach 1 is essentially the sole domain of the military. There’s an argument to be made that it’s one of the few areas of technological advancement where the state-of-the-art not only stopped moving forward, but actually slid backwards.
But that might finally be changing, at least in the United States. Both NASA and the private sector have been working towards a new generation of supersonic aircraft that address the key issues that plagued their predecessors, and a recent push by the White House aims to undo the regulatory roadblocks that have been on the books for more than fifty years.
The Concorde Scare
Those with even a passing knowledge of aviation history will of course be familiar with the Concorde. Jointly developed by France and Britain, the sleek aircraft has the distinction of being the only SST to achieve successful commercial operation — conducting nearly 50,000 flights between 1976 and 2003. With an average cruise speed of around Mach 2.02, it could fly up to 128 passengers from Paris to New York in just under three and a half hours.
But even before the first paying passengers climbed aboard, the Concorde put American aircraft companies such as Boeing and Lockheed into an absolute panic. It was clear that none of their SST designs could beat it to market, and there was a fear that the Concorde (and by extension, Europe) would dominate commercial supersonic flight. At least on paper, it seemed like the Concorde would quickly make subsonic long-range jetliners such as the Boeing 707 obsolete, at least for intercontinental routes. Around this time, the Soviet Union also started developing their own SST, the Tupolev Tu-144.
The perceived threat was so great that US aerospace companies started lobbying Congress to provide the funds necessary to develop an American supersonic airliner that was faster and could carry more passengers than the Concorde or Tu-144. In June of 1963, President Kennedy announced the creation of the National Supersonic Transport program during a speech at the US Air Force Academy. Four years later it was announced that Boeing’s 733-390 concept had been selected for production, and by the end of 1969, 26 airlines had put in reservations to purchase what was assumed to be the future of American air travel.
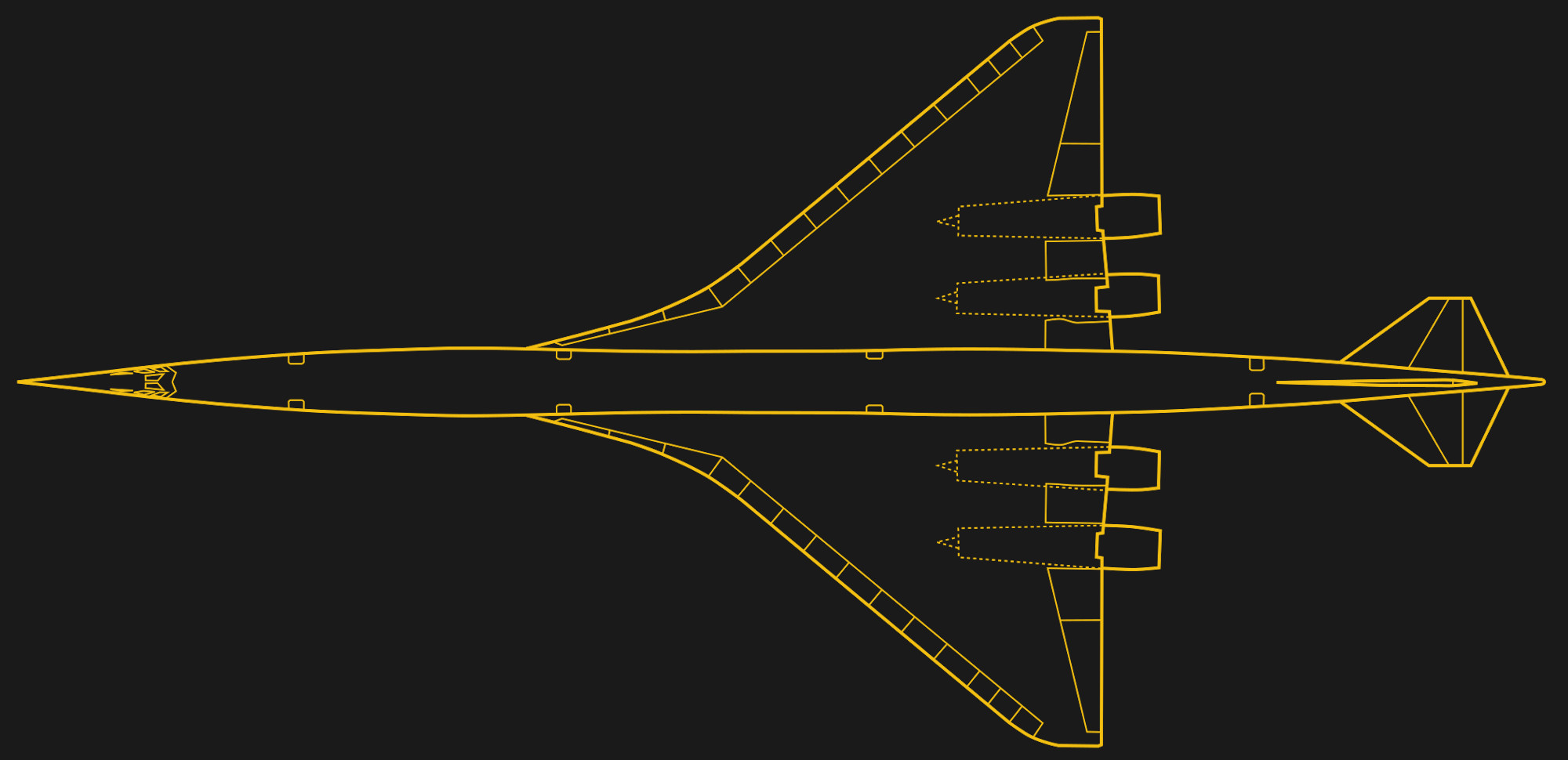
Even for a SST, the 733-390 was ambitious. It didn’t take long before Boeing started scaling back the design, first deleting the complex swing-wing mechanism for a fixed delta wing, before ultimately shrinking the entire aircraft. Even so, the redesigned aircraft (now known as the Model 2707-300) was expected to carry nearly twice as many passengers as the Concorde and travel at speeds up to Mach 3.
A Change in the Wind
But by the dawn of the 1970s it was clear that the Concorde, and the SST concept in general, wasn’t shaping up the way many in the industry expected. Even though it had yet to make its first commercial flight, demand for the Concorde among airlines was already slipping. It was initially predicted that the Concorde fleet would number as high as 350 by the 1980s, but by the time the aircraft was ready to start flying passengers, there were only 76 orders on the books.
Part of the problem was the immense cost overruns of the Concorde program, which lead to a higher sticker price on the aircraft than the airlines had initially expected. But there was also a growing concern over the viability of SSTs. A newer generation of airliners including the Boeing 747 could carry more passengers than ever, and were more fuel efficient than their predecessors. Most importantly, the public had become concerned with the idea of regular supersonic flights over their homes and communities, and imagined a future where thunderous sonic booms would crack overhead multiple times a day.
Although President Nixon supported the program, the Senate rejected any further government funding for an American SST in March of 1971. The final blow to America’s supersonic aspirations came in 1973, when the Federal Aviation Administration (FAA) enacted 14 CFR 91.817 “Civil Aircraft Sonic Boom” — prohibiting civilian flight beyond Mach 1 over the United States without prior authorization.

In the end, the SST revolution never happened. Just twenty Concorde aircraft were built, with Air France and British Airways being the only airlines that actually went through with their orders. Rather than taking over as the standard, supersonic air travel turned out to be a luxury that only a relatively few could afford.
The Silent Revolution
Since then, there have been sporadic attempts to develop a new class of civilian supersonic aircraft. But the most promising developments have only occurred in the last few years, as improved technology and advanced computer modeling has made it possible to create “low boom” supersonic aircraft. Such craft aren’t completely silent — rather than creating a single loud boom that can cause damage on the ground, they produce a series of much quieter thumps as they fly.
The Lockheed Martin X-59, developed in partnership with NASA, was designed to help explore this technology. Commercial companies such as Boom Supersonic are also developing their own takes on this concept, with eyes on eventually scaling the design up for passenger flights in the future.

In light of these developments, on June 6th President Trump signed an Executive Order titled Leading the World in Supersonic Flight which directs the FAA to repeal 14 CFR 91.817 within 180 days. In its place, the FAA is to develop a noise-based certification standard which will “define acceptable noise thresholds for takeoff, landing, and en-route supersonic operation based on operational testing and research, development, testing, and evaluation (RDT&E) data” rather than simply imposing a specific “speed limit” in the sky.
This is important, as the design of the individual aircraft as well as the environmental variables involved in the “Mach Cutoff” effect mean that there’s really no set speed at which supersonic flight becomes too loud for observers on the ground. The data the FAA will collect from these new breed of aircraft will be key in establishing reasonable noise standards which can protect the public interest without unnecessarily hindering the development of civilian supersonic aircraft.