Crunching The News For Fun And Little Profit
Do you ever look at the news, and wonder about the process behind the news cycle? I did, and for the last couple of decades it’s been the subject of one of my projects. The Raspberry Pi on my shelf runs my word trend analysis tool for news content, and since my journey from curious geek to having my own large corpus analysis system has taken twenty years it’s worth a second look.
How Career Turmoil Led To A Two Decade Project

In the middle of the 2000s I had come out of the dotcom crash mostly intact, and was working for a small web shop. When they went bust I was casting around as one does, and spent a while as a Google quality rater while I looked for a new permie job. These teams are employed by the search giant through temporary employment agencies, and in loose terms their job is to be the trained monkeys against whom the algorithm is tested. The algorithm chose X, and if the humans also chose X, the algorithm is probably getting it right. Being a quality rater is not in any way a high-profile job, but with the big shiny G on my CV I soon found myself in demand from web companies seeking some white-hat search engine marketing expertise. What I learned mirrored my lesson from a decade earlier in the CD-ROM business, that on the web as in any other electronic publishing medium, good content well presented has priority over any black-hat tricks.
But what makes good content? Forget an obsession with stuffing bogus keywords in the text, and instead talk about the right things, and do it authoritatively. What are the right things in this context? If you are covering a subject, you need to do so using the right language; that which the majority uses rather than language only you use. I can think of a bunch of examples which I probably shouldn’t talk about, but an example close to home for me comes in cider. In the UK, cider is a fermented alcoholic drink made from apples, and as a craft cidermaker of many years standing I have a good grasp of its vocabulary. The accepted spelling is “Cider”, but there’s an alternate spelling of “Cyder” used by some commercial producers of the drink. It doesn’t take long to realise that online, hardly anyone uses cyder with a Y, and thus pages concentrating on that word will do less well than those talking about cider.
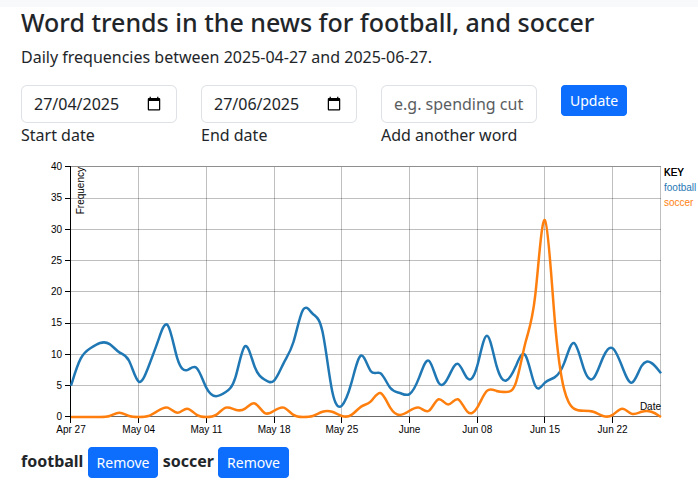
I started to build software to analyse language around a given topic, with the aim of discerning the metaphorical cider from the cyder. It was a great surprise a few years later to discover that I had invented for myself the already-existing field of computational linguistics, something that would have saved me a lot of time had I known about it when I began. I was taking a corpus of text and computing the frequencies and collocates (words that appear alongside each other) of the words within it, and from that I could quickly see which wording mattered around a subject, and which didn’t. This led seamlessly to an interest in what the same process would look like for news data with a time axis added, so I created a version which harvested its corpus from RSS feeds. Thus began my decades-long project.
From Project Idea, To Corpus Appliance
In 2005 I knew how to create websites in the manner of the day, so I used the tools I had. PHP5, and MySQL. I know PHP is unfashionable these days, but at the time this wasn’t too controversial, and aside from all the questionable quality PHP code out there it remains a useful scripting language. Using MySQL however would cause me immense problems. I had done what seemed the right thing and created a structured database with linked tables, but I hadn’t fully appreciated just how huge was the task I had taken on. Harvesting the RSS firehose across multiple media outlets brings in thousands of stories every week, so queries which were near-instantaneous during my first development stages grew to take many minutes as my corpus expanded. It was time to come up with an alternative, and I found it in the most basic of OS features, the filesystem.
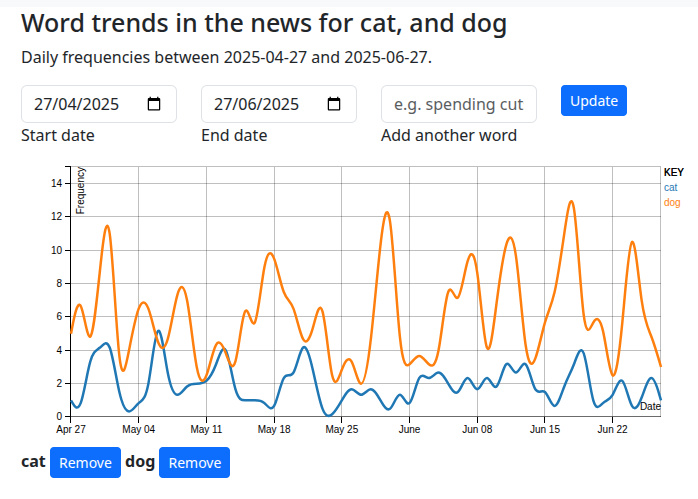
Casting back to the 1990s, when you paid for web hosting it was given in terms of the storage space it came with. The processing power required to run your CGI scripts or later server-side interpreters such as ASP or PHP, wasn’t considered. It thus became normal practice to try to reduce storage use and not think about processing, and I had without thinking followed this path.
But by the 2000s the price of storage had dropped hugely while that of processing hadn’t. This was the decade in which cloud services such as AWS made an appearance, and as well as buying many-gigabyte hard disks for not a lot, you could also for the first time rent a cloud bucket for pennies. My corpus analysis system didn’t need to spend all its time computing if I could use a terabyte hard drive to make up for less processor usage, so I turned my system on its head. When collecting the RSS stories my retrieval script would pre-compute the final data and store it in a vast tree of tiny JSON files accessible at high speed through the filesystem, and then my analysis software could simply retrieve them and make its report. The system moved from a hard-working x86 laptop to a whisper-quiet and low powered Raspberry Pi with a USB hard disk, and there it has stayed in some form ever since.
Just What Can This Thing Do?
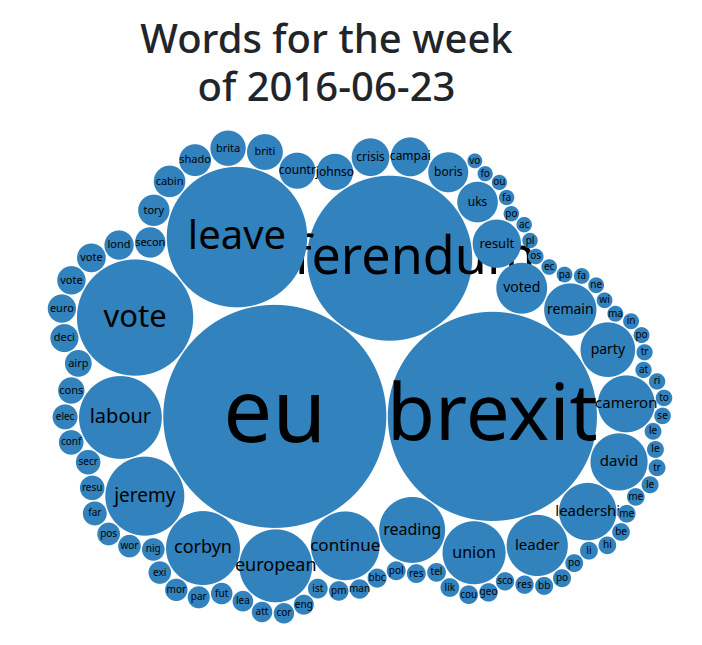
So I have a news corpus that has taken me a long time to build. I can take one or more words, and I can compare their occurrence over time. I can watch the news cycle, I can see stories build up over time. I can even see trends which sometimes go against received opinion, such as spotting that the eventual winner of the 2016 UK Labour leadership race was likely to be Jeremy Corbyn early on while the herd were looking elsewhere. Sometimes as with the performance of the word “Brexit” over the middle of the last decade I can see the great events of our times in stark relief, but perhaps it’s in the non-obvious that there’s most value. If you follow a topic and it suddenly dries up for a couple of days, expect a really big story on day three, for example. I can also see which outlets cover one story more than another, something helpful when trying to ascertain if a topic is being pushed on behalf of a particular lobby.
My experiment in text analysis then turned into something much more, even dare I say it, something I find of help in figuring out what’s really going on in turbulent times. But from a tech point of view it’s taught me a huge amount, about statistics, about language, about text parsing, and even about watching the number of available inodes on a hard drive. Believe me, many millions of tiny files in a tree can become unwieldy. But perhaps most of all, after a lifetime of mucking about with all manner of projects but generating little of lasting significance, I can look at this one and say I created something useful. And that is something to be happy about.